MI Lab Overview¶
Data scientists and data engineers can perform data exploration, develop and manage machine learning models in the MI Lab.
The MI Lab provides data scientists with an interactive working environment for a series of experimental operations, including data exploration, model training, model tuning, and model evaluation. Data scientists can use data sets to create models in the experimental environment, and the codes for model training can be solidified into Workflow operators for continuous model training tasks. The model file finally generated by the model training can be used as the input of model staging and deployment in the MI Hub.
The following figure shows the process of the data exploration, training, and development of machine learning models in the MI Lab:
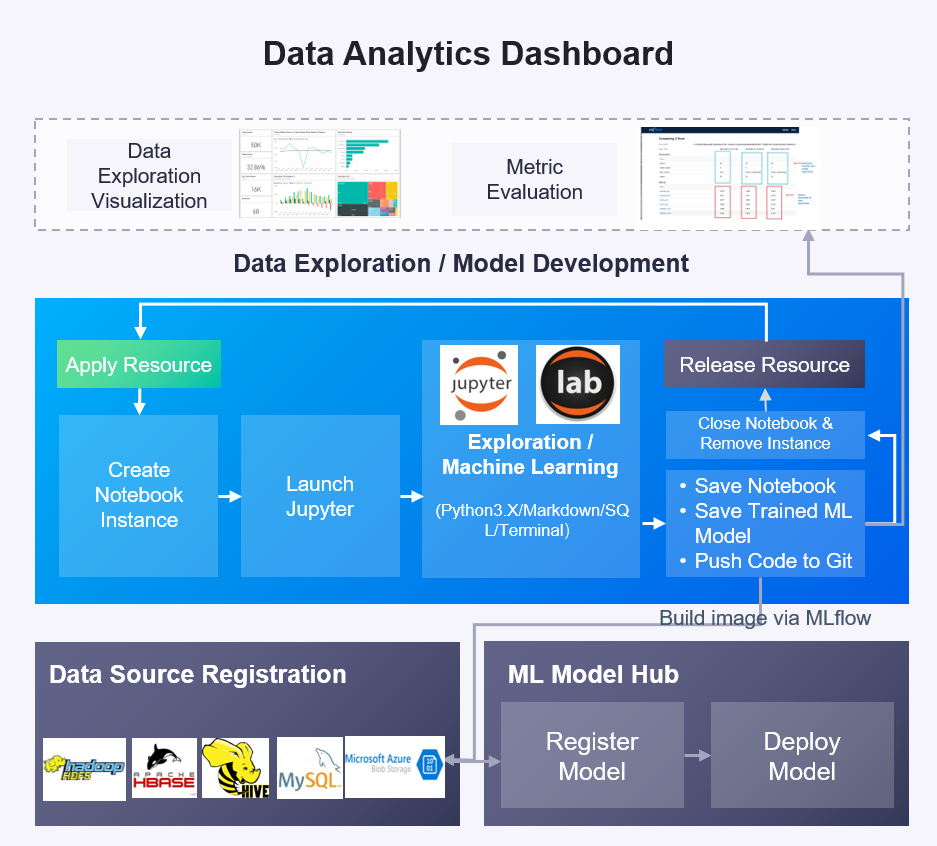
Main Functions¶
Integrating JupyterLab¶
Jupyter is the most popular data exploration tool and development environment for machine learning developers. The MI Lab integrates JupyterLab to provide a model development and authoring environment for data scientists.
Online Collaborative Development Environment¶
The MI Lab provides an online collaborative development environment for data scientists and algorithm engineers. Its features include:
- Easy to maintain: System administrators can uniformly make standard Notebook images and manage key certificates to ensure the stable operation of Notebook applications.
- Environment sharing: Different users can share the same Notebook environment in the cloud to achieve efficient collaboration.
- Resource management: The system can dynamically allocate required resources for different Notebooks.
- Permission management: It can work with other components of the Enterprise Analytics Platform to achieve unified authentication and permission management, and different teams can configure their own Notebook access permissions.
Tracking Experiment Results¶
The MI Lab can track and record the running results and metrics of each experiment. After the machine learning codes are executed, the parameters, code version, performance evaluation, and output files will be recorded to facilitate the later visualization and the tracking of experimental parameters and performance indicators.
Distributed Training Acceleration¶
The Enterprise Analytics Platform leverages the flexible resource scheduling and distributed operation capabilities of the underlying container. By customizing third-party resources and controllers, it provides distributed training task management for popular machine learning libraries, such as TensorFlow and PyTorch, which helps to significantly reduce the training cycle of complex models.